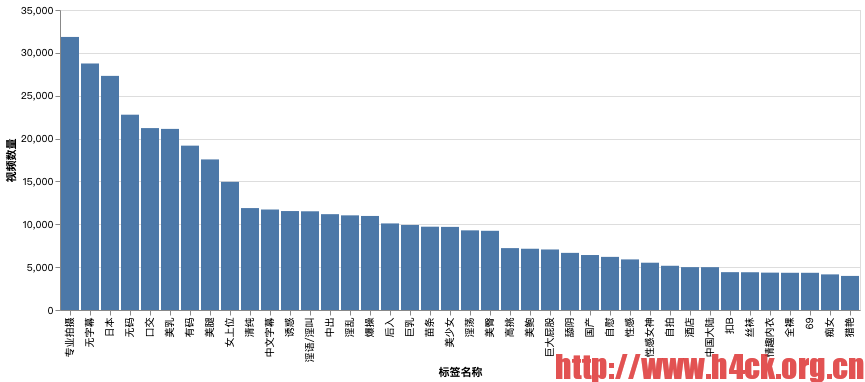
from pyspark.sql.functions import col
import altair as alt
import pandas as pd
from matplotlib import pyplot as plt
get_ipython().run_line_magic('matplotlib', 'inline')
csv = spark.read.option("header",True).csv("hdfs://localhost:9000/data2/porn_data_movie_tags.csv")
tag_csv = spark.read.option("header",True).csv("hdfs://localhost:9000/data2/porn_data_tag.csv")
csv.show()
+---+--------+------+
| id|movie_id|tag_id|
+---+--------+------+
| 1| 9909| 1|
| 2| 9909| 2|
| 3| 9909| 3|
| 4| 9909| 4|
| 5| 9910| 5|
| 6| 9910| 6|
| 7| 9910| 7|
| 8| 9910| 8|
| 9| 9910| 9|
| 10| 9910| 10|
| 11| 9911| 12|
| 12| 9911| 2|
| 13| 9911| 1|
| 14| 9911| 13|
| 15| 9910| 11|
| 16| 9911| 14|
| 17| 9911| 15|
| 18| 9911| 5|
| 19| 9910| 16|
| 20| 9910| 17|
+---+--------+------+
only showing top 20 rows